哈囉~雖然資料前處理的階段已經結束了,產出今天要介紹的各位皇親國戚應該還算是在前處理的範圍內,畢竟特徵萃取不太能算在模型訓練的一環,好吧反正他們就是地位尷尬啦。即便如此,如果你不認識這些皇族的話,大概在看九成的機器學習相關資料都會遇到問題,所以一起來看看他們都是些什麼貴重人物吧~
N-Gram是一種用來計算詞頻的方法。N代表的是未知數,也就是說裡面可以填入任何數字。如果選擇填入1,那就叫做unigram,是以一個字(詞)為單位計算的詞頻;如果選擇填入2,那就叫做bigram,是以兩個字(詞)為單位計算的詞頻;如果選擇填入3,那就叫做trigram,是以三個字(詞)為單位計算的詞頻,數字可以一直加上去,依此類推。下面的圖是中文跟英文具體的例子。


問題來了,為什麼我們會需要bigram、trigram甚至更多gram呢?直接用unigram算詞頻不好嗎,幹嘛搞得這麼複雜咧?這就要請大家回想昨天提到詞袋模型有什麼缺點了。詞袋模型基本上就跟unigram,也就是俗稱的詞頻一樣,只是計算一個詞出現在文本裡面的頻率。雖然能一定程度表現出文本的重點跟特色,卻忽略了語言也是有順序性的。同樣的詞彙組合會因為順序不同而產生完全不一樣的意思,而這樣的特色卻沒有辦法透過unigram或BOW表現出來,所以我們才會需要bigram跟trigram,甚至是數字更多的gram。因為他們維持了部分原來語料中的順序性,比unigram更能反應出語意相關的資訊。
N-gram常常被用來計算一個句子出現的機率,所以也可以算是一種語言模型,而且他是NLP發展早期最被普遍使用的語言模型之一。正常來說,如果我們想計算This is a book.出現的機率,我們需要知道This出現的機率、is出現在This後面的機率、a出現在This is後面的機率、book出現在This is a後面的機率,把這些數值相乘之後才能得到This is a book出現的機率(應該不難理解,就是一個一個乘上去的概念)。然後把這個簡化成公式就會像下面這樣:
但在N-gram的假設底下,一個字的出現只會被他前(N-1)個字影響。也就是說如果我今天想做一個bigram模型,那每個字的出現都只會受到前1個字的影響。因此公式可以被簡化成這樣: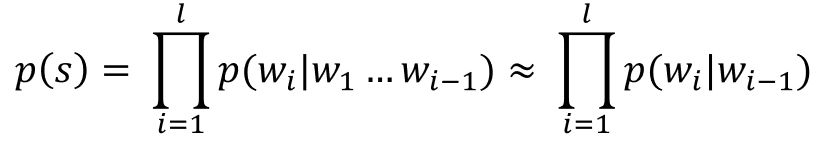
如果你現在覺得上面的話看起來有點眼熟,沒有錯,這跟馬可夫模型的假設相同,N-Gram確實是一種馬可夫模型的應用。為了讓句首跟句尾的字可以跟其他人一樣整整齊齊的,我們會在最前面跟最後面分別加上標籤。所以按照剛剛的例句走的話,就會變成<BOS>This is a book<BOS>(BOS, Boundary of Sentence)。而這個句子出現的機率就會是P(This|<BOS>)×P(is|This)×P(a|is)×P(book|a)×P(<BOS>|book)。這些機率都是透過我們擁有的語料內容(通常需要最少上百萬字的語料)去計算出來的。
這樣的計算方法會遇到一個很大的問題,萬一有語料庫裡面沒出現過的字,不管我們現在計算的是幾個gram,都會面臨因為其中一個機率為0,而讓整個計算結果歸零的問題(因為是全部乘起來的關係,國小數學大家應該都 懂)。為了解決這個問題,前人研究了各種方法來讓N-Gram的計算更加精確,我們把這些讓算法變得更好的動作稱為smoothing。其中一個最單純的解決方法就幫每個詞的出現次數都加1,這樣就不會有0出現的問題。聽起來很理想,但其實還有其他問題存在。不過這不是我們今天要討論的東西所以就不多做說明,現在只需要知道N-Gram的原理就可以了~(如果有興趣看各種不同smoothing的方法,可以在文末點今天第一篇參考資料的連結)
不知道有多少人想到這個問題,剛開始學這些概念的時候我根本沒意識到還需要提出這樣的問題。直到課堂上老師問我們「你們覺得BOW跟unigram和詞頻一樣的東西嗎?」我才開始思考。嗯...算法都是一樣的,應該一樣吧?接著老師又提問了:「如果一樣幹嘛需要這麼多名字?」對誒...如果一樣幹嘛需要這麼多名字啊?是像綽號一樣嗎?事實證明老師之所以是老師,我之所以是學生,都有原因的(並不是年紀大小的問題=)),跟我這種想法淺薄的人完全不同。所以他們之間到底有什麼區別呢?算法確實是一樣的,但名字不同不是為了幫他們取綽號,而是因為這三個東西使用的目的並不相同。詞頻我們在斷詞的時候就提過了,計算它的目的是為了知道文本的重點在哪裡;詞袋模型的部分則是比較常被拿來做one-hot encoding讓文字轉換成電腦可以讀懂的向量;最後unigram所屬的N-gram則是用來計算句子出現的機率。All in all, 當我們為了不同目的,使用同樣的這個方法,就要特別注意自己的選詞是否精確。這可是能看出我們到底有沒有真正理解概念的關鍵喔。
不是我不寫他的中文名字,是他真的沒有。但這也是一個從字面意思就可以看到概念全貌的名詞,所以就聽我娓娓道來吧~如果撇除掉詞頻不考慮先後順序的問題,他還有沒有其他問題呢?有的。當我們在做機器學習的時候,常常都是在做分類任務,所以很重要的一件事就是要區辨出兩個類別的不同。但是只找出詞頻真的就可以代表一個文本的特徵嗎?有沒有可能其實我在這這篇文本裡面找出來詞頻高的字在別的文本裡面詞頻也很高呢?當然有可能。而這也就代表其實我們找出來的這個詞不足以稱為特徵。醜小鴨在鴨群裡面跟大家都長得不一樣所以總是被欺負,但是真的回到天鵝群以後大家都一樣,根本就沒有人在意他長得怎樣。因為你有我有大家有的東西就很普通,也不能用來區別我們之間的不同。為了避免認錯特徵的狀況發生,我們可以做的事情就是把這個詞在其他資料裡面出現的頻率也一起納入考量。所以TF-IDF實際上就是Term Frequency(詞頻)乘上Inversed Document Frequency(一個詞在一群檔案裡面的普遍度)的結果而已。
IDF的計算方法是把所有文本的數量除上有出現目標詞彙的檔案數量(其實還要取log,但原因比較複雜,這邊先不討論),所以目標詞出現的文本數量越少就會得到越大的數字,同時也代表著他的特殊性。當一個詞彙既在目標文本裡面出現頻率高又在所有文本裡面不普遍,就可以得到比較大的數值,以此驗證他對目標文本的代表性。
需要特別注意的是這邊提到的所有文本其實有兩個種類,而使用哪個就是我們的目的去判斷了。這邊第一種方法是在我們取得的資料之外又從別的地方找不同類型的文本來計算,這麼做的目的是為了瞭解我們手上這種類型的資料到底實際上特別在哪裡,怎麼跟其他種類區別開來。第二種方法則是只用我們手上的資料去計算。這樣做的目的可能就是希望只針對我們分類任務要區分的對象去看他們之間有沒有什麼不同。因此要用哪個方式做就看個人需求,當然也可以同時看囉。
上面介紹的TF-IDF計算方法只是最基礎的,跟N-gram一樣有一些缺點,也有很多smoothing的方法,如果有興趣了解的話,一樣可以找相關文章來看。但基本上非從業人員直接用套件解決就可以了,差別就在你想不想成為pro而已。
因為理解概念已經很燒惱了,今天就先不帶N-gram跟TF-IDF的實作,我會把他們留到後面講模型的時候再穿插進去。那就明天見啦~
An Empirical Study of Smoothing Techniques for Language Modeling

